djangoで物体検出
はじめに
前回はなんとかvscodeを使って、djangoをUbuntu上で動かしてみました。
今回はHello,Worldでないアプリを作ろうと考え、pythonらしく物体検出でもやってみることにしました。と、言っても検出ロジックは丸パクリです。
PythonでOpenCV DNNを利用して物体検知(Object Detection)する方法 | HaneCa
DNNはおろか、OpenCVすらよく分かってません。
仕様
- ユーザーがサイトに来る
- アプリがトップページを返す
- ユーザーが画像を指定してアップロードする
- アプリが画像から物体検出する
- アプリが検出済み画像をファイルに出力する
- アプリがファイルに出力した画像を挿し込んだトップページを返して3に戻る
リクエストが複数同時に来たときの仕様がありませんが、今回は固定ファイルに上書きします。結果は神のみぞ知るスタイルです。
設計
- 画像あり/なしで表示を分けられるテンプレートトップページ
- モデル空
- 物体検出は固有のモデルでもビューでもフォームでもないものに実装
- ビューで画像を受け取り、物体検出を呼び出し、結果を受けてテンプレートを呼び出す
実装
環境調整
djangoのような大きなモジュールをpipでインストールすると、vscodeのファイル監視が許容量オーバーしてしまいます。
Running Visual Studio Code on Linux
にあるように、システムの最大監視数を増やします(8,192→524,288)。
echo fs.inotify.max_user_watches=524288 | sudo tee -a /etc/sysctl.conf
sudo sysctl -pこれでvscodeを起動し直して、警告が出なければ大丈夫です。
でもって、新しくアプリケーション作るため、vscodeのターミナルから以下を実行します。
python manage.py startapp detect_appフェーズ1
まずは物体検出を行わず、受け取った画像そのものを返して実装。つまり物体検出はハリボテ(モック)。
ビューはこんな感じ。コントローラがないので、全てビューで記述してます。受け取ったファイルの検証はしてません(公開は出来ない)。
from django.http import HttpResponseRedirect
from django.shortcuts import render
from .apps import DetectAppConfig
from .forms import UploadFileForm
from .upload import handle_uploaded_file
from .detect import detect
def upload_file(request):
result = None
if request.method == 'POST':
form = UploadFileForm(request.POST, request.FILES)
if form.is_valid():
input_path = DetectAppConfig.image_filebase + DetectAppConfig.image_file_input
output_path = DetectAppConfig.image_filebase + DetectAppConfig.image_file_output
output_url = DetectAppConfig.image_urlbase + DetectAppConfig.image_file_output
handle_uploaded_file(request.FILES['file'], input_path)
detect(input_path, output_path)
result = output_url
else:
form = UploadFileForm()
return render(request, 'detect_app/upload.html', {'form': form, 'result': result})中で使用されているフォームがこんな感じ。見事にファイルだけです。
from django import forms
class UploadFileForm(forms.Form):
file = forms.FileField()HTMLのテンプレートがこんな感じ。Bootstrap4を使ってますが、見た目はやはりアレです?。また画像ファイルのチェックをしていません(公開不可)。フォームデータと抽出結果のURLを渡されてビューから呼ばれます。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<title>物体検出</title>
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css"
integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous">
</head>
<body class="bg-light">
<div class="container">
<div class="py-5 text-center">
<h1>物体検出</h1>
</div>
<div class="row justify-content-center">
<form method="post" enctype="multipart/form-data">
{% csrf_token %}
<div>
<label>画像ファイル</label>
</div>
<div>
{{form.file}}
</div>
{% if result %}
<div>
<img src="{{ result }}" class="img-responsive">
</div>
{% endif %}
<hr>
{% for error in form.file.errors %}
{{error}}
{% endfor %}
<button class="btn btn-primary btn-lg btn-block" type="submit">送信</button>
</form>
</div>
</div>
</body>
</html>そしてこれがハリボテ本体。
import shutil
def detect(input, output):
shutil.copy2(input, output)他にも設定ファイルなどはいじってますが、最後にgitを張るので省略します。フェーズ1はこんな感じです。
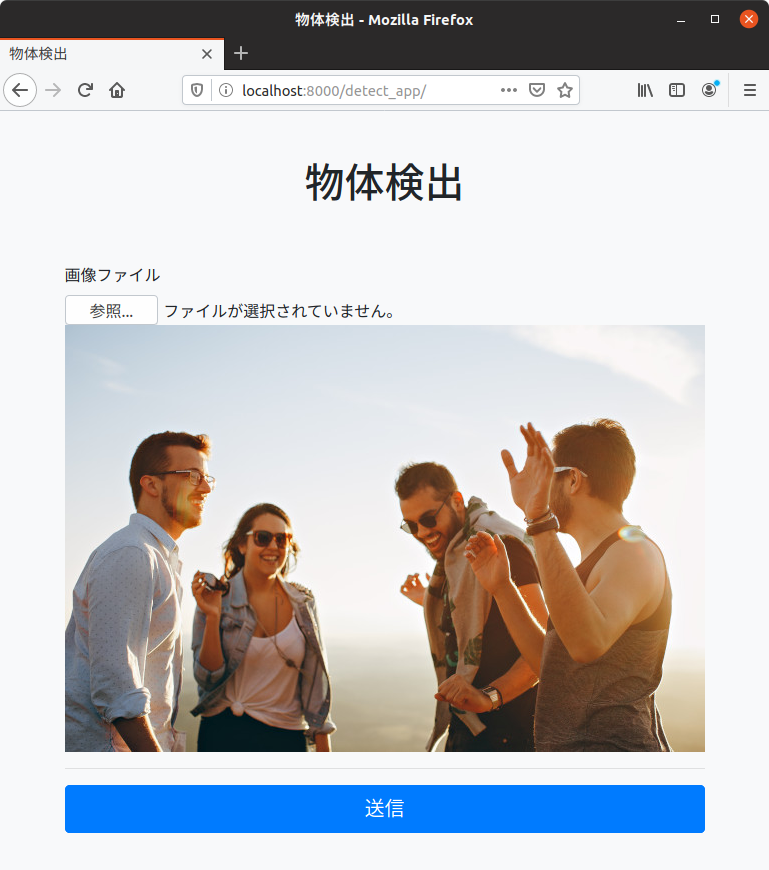
入力画像は下のサイトのをお借りしました(超綺麗な写真なので縮小したけど)。ありがとうございます。
Group of People Having Fun Together Under the Sun · Free Stock Photo
フェーズ2
いよいよ物体検出です。まずはpythonにパッケージの追加から。
pip install opencv-python
pip freeze > requirements.txtこのまま実装するとpylintがopencvを認めてくれないので、設定でpython.linting.pylintArgsを検索して、[項目追加]

「–extension-pkg-whitelist=cv2」を追加する。
でもdnnはこれでもダメなようです。うまく回避する方法は見つかりませんでした。ドキュメントコメントがないと怒られてるワーニングも大量にあるので、これ以上は諦めます。
では、気を取り直して実装します。中身を入れたdetect.pyです。
import cv2
def detect(input, output):
classes = {0: 'background',
1: 'person', 2: 'bicycle', 3: 'car', 4: 'motorcycle', 5: 'airplane', 6: 'bus',
7: 'train', 8: 'truck', 9: 'boat', 10: 'traffic light', 11: 'fire hydrant',
13: 'stop sign', 14: 'parking meter', 15: 'bench', 16: 'bird', 17: 'cat',
18: 'dog', 19: 'horse', 20: 'sheep', 21: 'cow', 22: 'elephant', 23: 'bear',
24: 'zebra', 25: 'giraffe', 27: 'backpack', 28: 'umbrella', 31: 'handbag',
32: 'tie', 33: 'suitcase', 34: 'frisbee', 35: 'skis', 36: 'snowboard',
37: 'sports ball', 38: 'kite', 39: 'baseball bat', 40: 'baseball glove',
41: 'skateboard', 42: 'surfboard', 43: 'tennis racket', 44: 'bottle',
46: 'wine glass', 47: 'cup', 48: 'fork', 49: 'knife', 50: 'spoon',
51: 'bowl', 52: 'banana', 53: 'apple', 54: 'sandwich', 55: 'orange',
56: 'broccoli', 57: 'carrot', 58: 'hot dog', 59: 'pizza', 60: 'donut',
61: 'cake', 62: 'chair', 63: 'couch', 64: 'potted plant', 65: 'bed',
67: 'dining table', 70: 'toilet', 72: 'tv', 73: 'laptop', 74: 'mouse',
75: 'remote', 76: 'keyboard', 77: 'cell phone', 78: 'microwave', 79: 'oven',
80: 'toaster', 81: 'sink', 82: 'refrigerator', 84: 'book', 85: 'clock',
86: 'vase', 87: 'scissors', 88: 'teddy bear', 89: 'hair drier', 90: 'toothbrush'}
# Load a model imported from Tensorflow
tensorflowNet = cv2.dnn.readNetFromTensorflow('./model/frozen_inference_graph.pb', './model/graph.pbtxt')
# Input image
img = cv2.imread(input)
rows, cols, channels = img.shape
# Use the given image as input, which needs to be blob(s).
tensorflowNet.setInput(cv2.dnn.blobFromImage(img, size=(300, 300), swapRB=True, crop=False))
# Runs a forward pass to compute the net output
networkOutput = tensorflowNet.forward()
# Loop on the outputs
for detection in networkOutput[0,0]:
score = float(detection[2])
if score > 0.2:
left = detection[3] * cols
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
#draw a red rectangle around detected objects
cv2.rectangle(img, (int(left), int(top)), (int(right), int(bottom)), (0, 0, 255), thickness=2)
#draw category name in top left of rectangle
cv2.putText(img, classes[int(detection[1])], (int(left), int(top-4)), cv2.FONT_HERSHEY_PLAIN, 1, (0, 0, 255), 2, 8)
cv2.imwrite(output, img)動かすにはトレーニング済みモデルデータと設定ファイルがいるのですが、これをダウンロードするスクリプトが↓です。
#!/bin/sh
mkdir -p model
wget -O - 'http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v2_coco_2018_03_29.tar.gz' | tar xvfzO - ssd_mobilenet_v2_coco_2018_03_29/frozen_inference_graph.pb > model/frozen_inference_graph.pb
wget -O - 'https://raw.githubusercontent.com/opencv/opencv_extra/master/testdata/dnn/ssd_mobilenet_v2_coco_2018_03_29.pbtxt' > model/graph.pbtxtサーバー起動して、POSTしてみると…
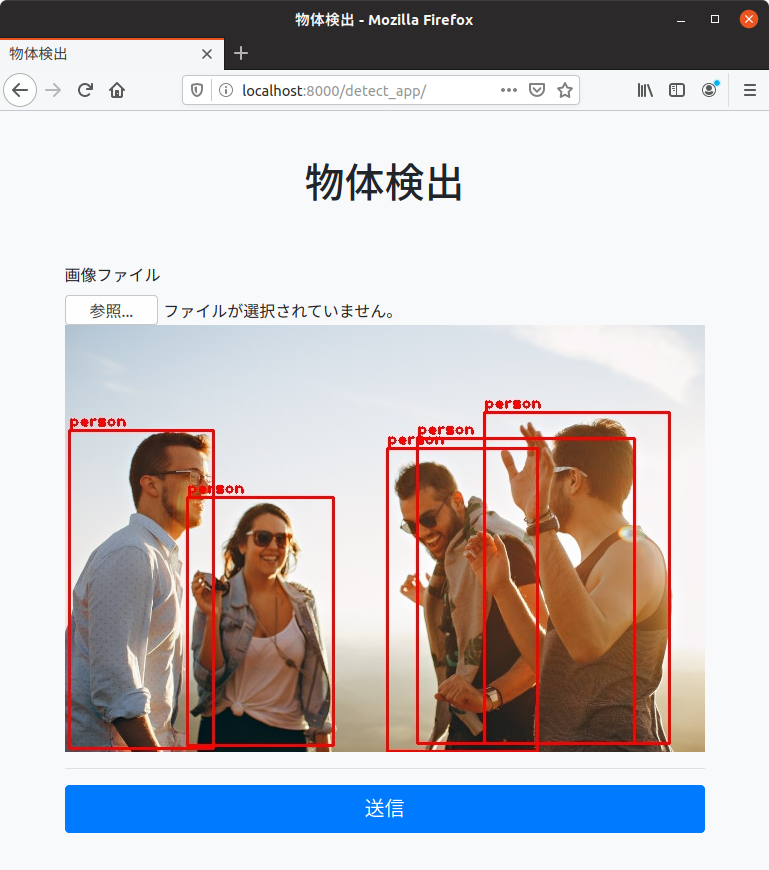
一人多いですね。
前回と同じですが、このサーバーのGitList
Giteaです。
デバッグ
djangoのデバッグも特別なことはありません。デバッグメニューからデバッグの開始を選びます。
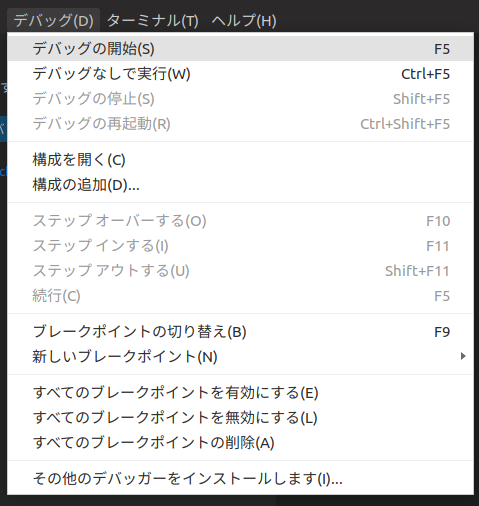
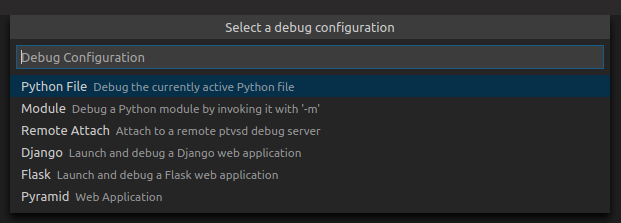
Pythonを選びます。

Djangoを選びます。
ブレークポイントを張ります。
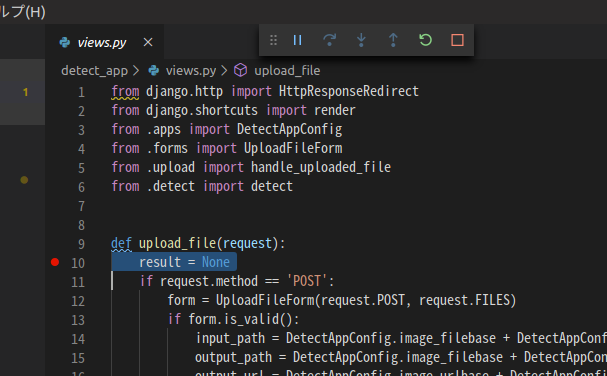
アップロードしてみます。
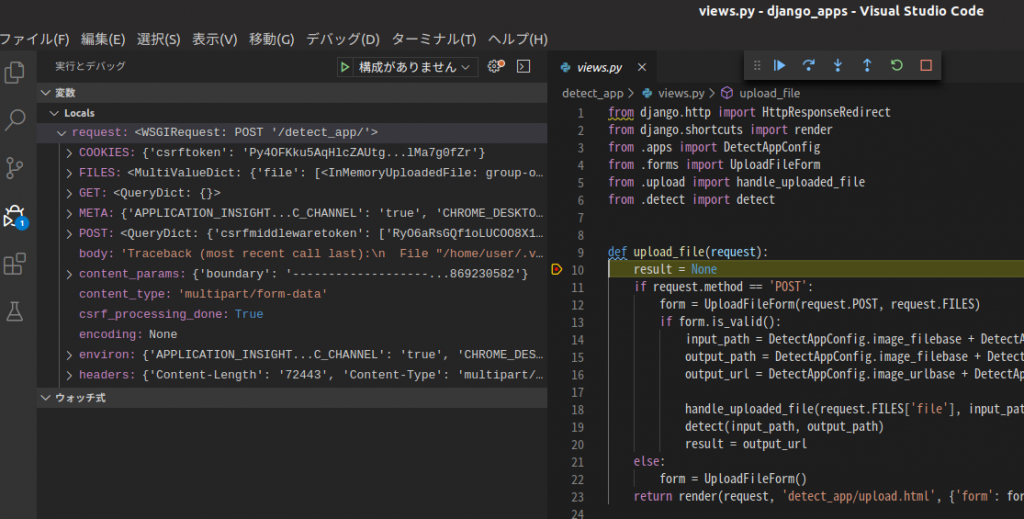
こんな感じで止まりました。変数も普通に見えてます。他と変わりません。
まとめ
今回はdjangoで物体検出するアプリを作って、デバッグまでしてみました。
次回はこのアプリを進化させ、モデルも使って、PostgreSQLにデータを入れてみたいと思います。